« Accéder à des données nouvelles, les stocker, les trier, les croiser… tous les acteurs de l’action publique le savent, cela ne s’improvise pas. A fortiori lorsque l’on souhaite expérimenter des méthodes nouvelles qui vont compléter des outils statistiques traditionnels par des outils algorithmiques susceptibles de modéliser la manière dont vivent les quartiers »
Pendant 3 ans, l’association RésO Villes a entrepris de jeter une passerelles « entre deux univers qui ne se connaissaient pas : celui de la politique de la ville et celui de la data ».
Avec le soutien de l’Agence Nationale de la Cohésion des Territoires (ANCT) et en s’appuyant sur les experts de CIVITEO, le programme « Data & Quartiers » a expérimenté de nouveaux outils et de nouveaux usages de la donnée que l’on retrouve plus fréquemment déployés dans les quartiers centraux au titre des projets de « ville intelligente ».
Les objectifs principaux du programme étaient les suivants :
▪ Utiliser des outils de « datascience » au bénéfice des quartiers prioritaires ;
▪ Améliorer la connaissance et l’observation des quartiers grâce à la donnée ;
▪ Comprendre et expliquer ces nouveaux outils, ces nouvelles données, ces nouveaux usages ;
▪ Documenter la méthodologie pour favoriser la duplication des expérimentations.
Les projets menés sur les thématiques de l’emploi, de la santé et des mobilités, avec le soutien de partenaires privés et publics, ont permis de consolider une méthodologie et d’acquérir certaines convictions quant au rôle de la donnée dans la politique de la ville.
Référence :
Les objectifs initiaux du programme « Data & Quartiers »
Utiliser des outils de la science des données dans les quartiers
En 2018, les Quartiers Prioritaires ne font pas partie des terrains d’expérimentations de ces nouveaux usages. RésO Villes a fait le choix d’engager une réflexion sur l’utilité des outils de la science des données pour résoudre des problématiques spécifiques des quartiers. L’enjeu central du programme va être de mobiliser des données disponibles à l’échelle des villes, quelle qu’en soit la source, pour proposer de nouvelles méthodes d’observation des quartiers. Les outils utilisés dans des quartiers « intelligents » des centres villes arrivent dans les quartiers périphériques.
Améliorer la connaissance et l’observation des quartiers grâce à la donnée
Il existe des indicateurs de suivi des quartiers, notamment auprès de l’Insee et de l’Observatoire national de la politique de la ville. Ces indicateurs permettent de suivre des statistiques utiles : démographie, emploi, pauvreté… Mais cette approche ne permet pas de connaître et de comprendre la vie quotidienne des habitant.e.s. Et pourtant des données existent, elles sont même de plus en plus nombreuses.
Documenter la méthodologie pour favoriser la duplication des expérimentations
En 2018, les projets recourant à la science des données ne sont pas très fréquents chez les acteurs publics, de surcroît à l’échelle de deux régions et dans une démarche partenariale associant des acteurs privés. Pour ces raisons, les partenaires de RésO Villes ont très vite insisté sur la nécessité de documenter les processus. Leur engagement dans le programme visait autant à comprendre (et à apprendre) la méthode qu’à accéder à des résultats inédits.
Tous les acteurs du programme ont été sensibilisés à cette démarche, y compris les prestataires réalisant des travaux de science des données. Il leur a constamment été demandé de documenter non seulement les méthodes et les outils retenus, mais aussi ceux qui ont été testés et laissés de côté.
Expliquer ces nouveaux outils, ces nouvelles données, ces nouveaux usages, ces nouveaux enjeux
« Data & Quartiers » avait un objectif plus large l’acculturation et la sensibilisation des différents acteurs du secteur public en général, et de la politique de la ville en particulier, sur les sujets de la donnée. À ce titre, diverses actions ont été menées auprès de publics variés ayant des niveaux de maturité numérique très disparates. Entre 2019 et 2022, de nombreux événements ont été organisés : conférences (à l’attention des conseillers citoyens de Bretagne et des Pays de la Loire, des responsables politique de la ville et/ou numériques des collectivités partenaires), conférences ouvertes à des acteurs territoriaux de la France entière organisées par l’Agence Nationale de la Cohésion des Territoires et le Centre National de la Fonction Publique Territoriale, des retours d’expérience auprès de différents centres de ressources politiques de la ville (Occitanie, PACA, Centre Val-de-Loire...)
La Méthodologie « Data & Quartiers »
Dès le départ, le programme « Data & Quartiers » a retenu un protocole en cinq étapes.
Étape n°1 : sensibiliser
L’étape de sensibilisation proposée à tous les acteurs du programme avait deux objectifs :
- un objectif général d’acculturation : la donnée est aujourd’hui au cœur de tous nos actes personnels, en tant que consommateur.rice.s, usager.e.s mais aussi citoyen.ne.s ;
- un objectif ciblé : définir ensemble les conditions du partage et de la mise à disposition de données en travaillant en commun les finalités des expérimentations à venir.
La sensibilisation dissipe les craintes éventuelles mais permet aussi de fixer les limites. L’acculturation peut se faire de différentes façons : une formation « théorique » présentant les enjeux, des ateliers de mise en situation des participants ou des séquences en ligne de type webinaire.
Étape n°2 : cadrer les besoins et définir les « cas d’usage » de la donnée
Pour chaque sujet, quel que soit le thème :
- Partir d’un constat ou d’une réalité. Débuter d’une photographie de la réalité éprouvée dans les quartiers prioritaires. Elle est fondée sur la connaissance du terrain des experts de la politique de la ville. À ce stade, il n’est pas encore question de donnée…
- Formuler une hypothèse. Une hypothèse est formulée pour améliorer la situation décrite préalablement. On commence à aborder la donnée comme un levier de résolution des difficultés rencontrées. On formule par exemple l’hypothèse que des données existent pour améliorer la connaissance des habitudes des habitant.e.s des quartiers (des données pour appréhender les difficultés d’accès à l’emploi, pour comprendre la prévalence de problématiques de santé, pour connaître les habitudes d’alimentation, pour connaître les pratiques culturelles…).
- Poser une problématique. La problématique prend la forme d’une question précise. C’est l’objet des travaux. Concise et directe, elle décrit les ambitions fixées par le groupe de travail. Par exemple : les habitant.e.s des quartiers sont-ils plus exposé.e.s que d’autres au Covid-19 ?
- Définir des objectifs. Les objectifs constituent la feuille de route de chaque groupe de travail : identifier des données, créer des conditions pour y accéder (s’il ne s’agit pas « d’open data »), les collecter, les croiser, produire de la visualisation des données…
- Identifier les données utiles: Chacun des projets du programme s’est appuyé sur une ou plusieurs séances d’exploration de données, que l’on appelle aussi le « datamining ». Cet exercice est bien connu des expert.e.s de la donnée, mais il est peu utilisé pour les politiques publiques locales, et encore moins à l’échelle des quartiers.
Étape n°3 : valider le cas d’usage / la preuve de concept
Accéder aux données. Au fil des mois, l’équipe de « Data & Quartiers » a développé une certaine expertise pour organiser l’accès aux données. Il y a d’un côté les données librement accessibles, et notamment les données en « open data » mises à disposition par l’Insee ou publiées par les communes. Mais il y a aussi d’autres données publiques non accessibles. Il s’agit de données produites par des acteurs publics, mais non rendues publiques. Il y a aussi des données privées. Elles sont produites par des entreprises qui acceptent de les mettre à disposition de RésO Villes au nom de l’intérêt général.
Préparer et explorer les données. Une fois les données collectées, il convient de s’assurer qu’elles sont exploitables au regard des objectifs. Les experts de la donnée prennent alors la main et vont explorer les différents fichiers et les bases de données mises à disposition. Ils vont notamment se pencher sur leur qualité : le format et le type de données, leur granularité (c’est-à-dire leur précision et leur fréquence de mise à jour), leur distribution et leur complétude (« a-t-on bien toutes les données utiles ? »), leur qualité (données aberrantes, incohérences…), etc. Cette phase peut donner lieu à des allers-retours entre les « fournisseurs » et les « explorateurs » de données afin de les enrichir et de les compléter.
Modéliser: En fonction des données disponibles et des objectifs à atteindre, les expert.e.s de la donnée vont appliquer une ou plusieurs techniques de modélisation. Il peut s’agir de modèles statistiques classiques ou d’algorithmes et de techniques plus avancés, y compris ayant recours à l’intelligence artificielle. Les expert.e.s de la donnée vont ainsi tester les jeux de données et voir si les informations que l’on espère en tirer vont en découler.
Évaluer le modèle. Les expert.e.s de la donnée appliquent leurs modèles sur les jeux de données de tests afin d’en comparer les performances. Les résultats obtenus sont ensuite présentés aux « experts métiers » afin d’en valider la pertinence. Parfois, il faut corriger les choses, par exemple en collectant des données différentes. Ce n’est qu’une fois la démarche validée, que l’on se lance dans un traitement à grande échelle des données. Appliquée à « Data & Quartiers », cette méthode a par exemple conduit à travailler sur 5 ou 6 quartiers sur des données de santé, avant d’étendre le travail aux 78 QPV de Bretagne et des Pays de la Loire.
Étape n°4 : prototyper la solution
Une fois vérifiée la pertinence des données et démontrée l’utilité de la modélisation (avec ou sans intelligence artificielle), il faut réfléchir à la manière de rendre les données « actionnables », c’est-à-dire trouver une forme de traitement des données qui va permettre aux acteurs de s’en servir de façon concrète. De nombreuses questions se posent : faut-il un outil que chacun peut manipuler à distance ? Faut-il une représentation statique (un tableau, une carte…) ? Comment représenter des données complexes à l’échelle de chaque quartier ? A l’échelle des villes ou des régions ? Les données doivent-elles être figées dans le temps ou faut-il prévoir de les actualiser ? Avec quel degré d’automatisation ?
Étape n°5 : mettre en production
Le programme « Data & Quartiers » dans sa version 2019-2022 était un programme expérimental. Il s’est arrêté à l’élaboration des prototypes. Mais l’objectif logique d’une démarche de science des données est de fournir ensuite des outils qui seront intégrés dans les processus de travail au quotidien.
Trois projets mis en œuvre dans le cadre de « Data & Quartiers »
Données et Emploi dans les quartiers : une étude sur les distances domicile-travail
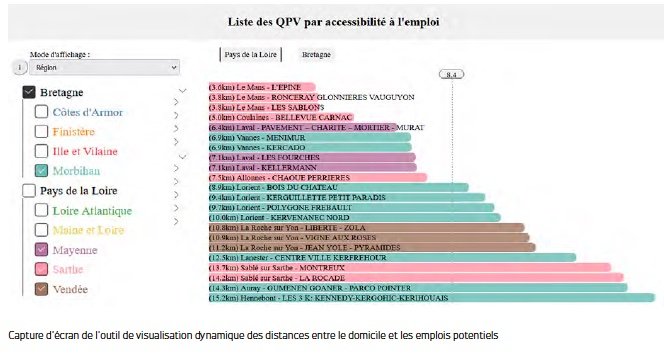
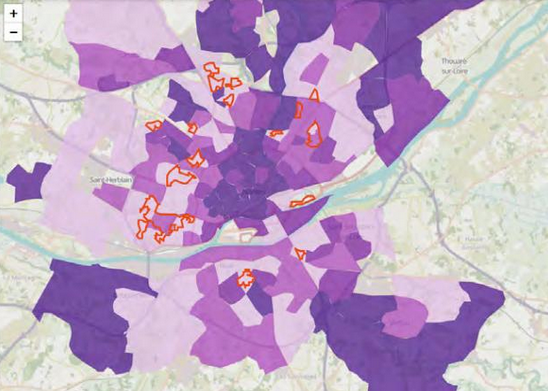
Le groupe de travail Emploi s’est fixé comme objectif d’étudier la réalité de la distance entre les métiers recherchés par les habitant.e.s des quartiers « politique de la ville » et les emplois à pourvoir qui y correspondent. Ce travail est réalisé par les équipes de science des données du groupe Randstad. Les données utiles à la résolution de cette problématique ont été transmises par Pôle emploi. Il s’agit des données des métiers les plus recherchés par les habitant.e.s des quartiers, d’après les déclarations effectuées lors des premiers entretiens avec les agents de Pôle emploi. Bien sûr, ces données sont anonymes. Elles ont ensuite été croisées avec les données des offres d’emploi à pourvoir, fournies par Randstad. Les cartographies produites permettent de visualiser la distance entre les emplois les plus recherchés par les habitants des quartiers et la localisation des offres d’emploi.
Données et Santé dans les quartiers : une étude sur la fragilité des habitants face au Covid-19
Différents travaux semblaient montrer que toutes les populations ne sont pas égales face au Covid-19, que certaines présentent des risques plus importants que d’autres d’être contaminées ou de développer des formes graves, et puisque des facteurs sanitaires ou sociaux étaient annoncés comme pouvant être à l’origine de cette inégalité, RésO Villes a souhaité objectiver la réalité des risques en Bretagne et Pays de la Loire.
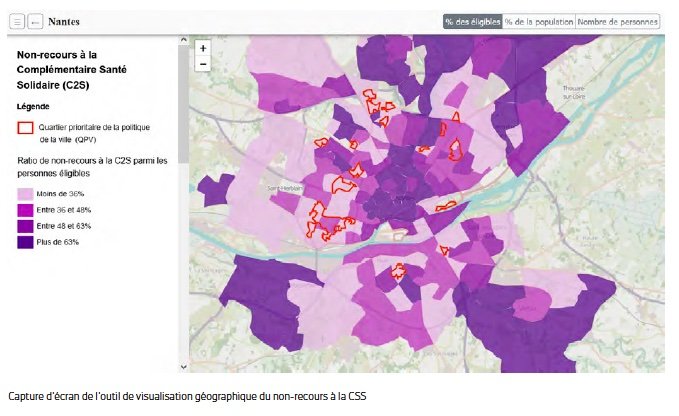
Le premier travail a été de sélectionner des indicateurs explicatifs d’une certaine fragilité face au virus : des indicateurs sanitaires et des indicateurs sociaux. Les indicateurs sociaux renvoient aux conditions de vie ou sociales des habitant.e.s des quartiers et permettent de cibler géographiquement ces habitant.e.s. L’avantage de ces données c’est qu’elles sont facilement accessibles, du moins à l’échelle des communes ou des IRIS. Des données existent sur le taux de personnes bénéficiaires de la CMU-C (devenue C2S), ou encore sur le taux de population vivant en logement HLM, ces deux éléments combinés révélant un niveau de ressources et un mode d’habitat Les données sanitaires été transmises par l’Observatoire régional de la santé de Bretagne.
L’équipe en charge des travaux de géomatique a livré dans un premier temps des cartographies statiques sur un nombre restreint de territoires. Puis un outil plus sophistiqué a été développé.
Les résultats des travaux valident à l’échelle locale les études nationales et internationales les ayant inspirés : toutes les populations ne sont pas égales face au Covid-19 et certaines présentent des risques plus importants d’être contaminés et/ou de développer des formes graves.
Pour la Bretagne, les résultats sont éloquents : les quartiers prioritaires de la ville (QPV) sont systématiquement situés au cœur des zones dans lesquelles le risque de fragilité face au Covid-19 est le plus fort (même si toutes les zones fragiles ne sont pas des QPV).
Données et Mobilités dans les quartiers : une étude sur les modalités de déplacement Domicile-Emploi
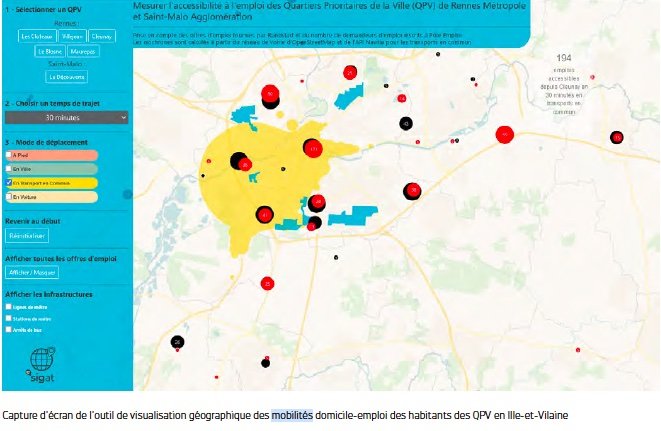
La distance domicile-travail opérée par les habitant.e.s des QPV ne peut représenter à elle seule, un critère déterminant dans la recherche d’un emploi. Identifier des distances entre domicile et emploi est une chose. Savoir comment s’y rendre en est une autre. Une convention de mise à disposition de données a d’abord été signée entre RésO Villes et l’Université de Rennes 2 pour permettre la réutilisation des données fournies par le Groupe Randstad et Pôle emploi. L’équipe de Rennes 2 a dans un premier temps, exploré l’ensemble des données fournies sur l’emploi disponible et les quartiers et construit une maquette d’un outil permettant de simuler les différentes manières d’accéder d’un QPV à un emploi donné. La première proposition reposait sur la création d’une carte dynamique permettant de sélectionner des offres d’emploi à l’intérieur d’isochrones. C’est-à-dire des tracés représentant les zones accessibles en un temps donné selon le mode de transport disponible. Le prototype livré par les étudiant.e.s est un véritable site web à l’ergonomie intuitive et conviviale comprenant un outil de géovisualisation associé à plusieurs outils de visualisation des données.
Quelques enseignements
« Passer d’une expérimentation comme celle-ci à une utilisation efficace et généralisée des données au service des acteurs de la politique de la ville ne se fera pas si facilement. L’expérience des métropoles pionnières en matière de gestion des données (pensons à Rennes et Nantes par exemple) peut nous être utile. Des nombreux « prototypes » restent parfois dans les cartons. Il faut réunir des conditions bien particulières pour installer dans la durée un pilotage avec des données.
Il faudra d’abord s’assurer que les données nécessaires qui ont été mises à disposition de façon expérimentale pourront l’être de façon pérenne. Cela peut prendre du temps. Et il y aura un coût. Ceci vaut aussi bien pour des acteurs publics (pensons par exemple aux extractions qui ont été faites par la CNAM) que des acteurs privés ...
Il faudra aussi que des acteurs soient formés et puissent les utiliser. L’étape d’acculturation, si importante dans le programme « Data & Quartiers » devra être organisée partout, auprès des élus, des agents territoriaux ou des acteurs associatifs. Et devra parfois être répétée.
Il faudra construire des outils techniques pour que la data science soit rendue accessibles aux acteurs de terrain : des interfaces, des flux et des tableaux de bord automatisés, des cartes interactives, des outils d’analyse « clef en main »… Tout ceci a un coût. L’intégration de ces coûts dans les prochains contrats de ville semble une nécessité.
Il faudra aussi prendre en compte des enjeux démocratiques et politiques. Une collectivité territoriale, un ministère, un centre de ressources… ce n’est ni Google, ni Facebook, ni Amazon ! L’utilisation massive des données mise au service de l’intérêt général se doit de respecter des règles qui vont bien au-delà du simple respect de la loi, notamment en matière de protection des données. Des acteurs engagés dans des politiques qui concernent des quartiers et des publics sensibles doivent se doter d’une éthique de la donnée. »
Linked articles
Digital technology and employment in priority city districts: when inequalities intersect


